
【短视频的病态传播将信息本身由原本的块状变成了洪流】
前言

最近不知怎么的又开始刷短视频了。。。
感觉刷短视频它像一个明明很容易戒,但是无时无刻都有人想让你换上这个瘾的一种精神药物,或者说是一个非常优秀的奶头乐工具,能让人几乎不付出任何成本,获得在信息摄取上的极大满足
我们都知道短视频不能多刷,但是我们每个人对于信息本身有像食物那样的渴望,太久没有大量摄入信息也会让我们产生焦虑和困惑。但是也正是像食物那样,过犹不及过多的信息输入会造成信息过载和精神耗散。
如果你的精力调度能力足够优秀,你可能会免于受到信息过载的影响,但是还有另外一个问题在等待着你——知识焦虑。
信息流本身就像很多压缩饼干,它本身能够在短时间内向用户展示大量的信息,这些信息当中除去那些没有用的日常新闻和娱乐项的短视频,它里面也会夹杂着很多高密度的知识信息。当然这些所谓的知识信息,很大程度上都是经过精心的抽象而成的,他在多数情况下对用户都是点到为止,让用户知道有这么个东西,但绝对不会深入的说。
但是这个时候有些喜欢钻牛角尖的人就开始痛苦了起来,因为这些信息告诉了他有很多他所不知道的东西,但是又没有完全告诉他这种戛然而止的感觉令人痛苦。同时当这些人真的开始进行这些方面的学习的时候,又会发现这些知识的体量太过于庞大,以至于他们根本无法像刷短视频那样把这些信息全部给收入到他们的脑中。
某种程度上是不是也是【无知是福】的一种体现(x)
第二大脑不是杂物仓
当然这里并不是说那些科普的知识项短视频博主他们是多么大的恶人,恰恰相反,在这个过程当中出问题的是用户本身。因为用户太过于贪心,所以他们会渴望只在几天的时间内就学完,原本可能需要到大学。花上三四年才能系统的学下来的知识体系。
也正是因为这种贪心,所以现在有很多怪象,比如说有些人会高价购买别人的笔记,然后把他们的笔记复制粘贴到自己的笔记内容当中,在此之后充其量记录一下这个笔记的位置,就再也没有去翻看了。然后这些人又会开始掰扯像是第二大脑或者知识仓库这样的概念来对这个行为本身做一个伪装。

倒不是说第二大脑或者知识仓库本身是什么太大的问题,问题还是在于用户自身。对这个理解出现了偏差,单纯的积累不会产生任何的价值。第二大脑和知识仓库的存在,更多的是方便人去检索。而绝大多数人连检索都懒得检索,他们只是单纯的把知识堆在那里,就像酿酒一样,他们仿佛希望通过时间的积累能酝酿出什么有价值的东西来似的。(当然这是不可能的啦)
尝试用RSS自建城墙
RSS其实也已经是一个非常老的一个技术了,这里对于它的技术细节和原理不做赘述,相关的资料网上都有很多。简而言之,它就像微信公众号那样(爷爷像孙子),是一个信息源的聚合
目前互联网上关于rss的开发和应用有很多,比如Feedly里和Rsshub等都是非常优秀的工具。但是他们或多或少都有一些问题,比如说拓展性的局限以及付费的问题。
随着大语言模型时代的到来,这些工具多少也成了一下东风,比如飞得利里面就提供了一个解决方案,用户可以通过订阅会员的方式,获得让ai来总结当日的内容的服务(只不过这个服务目前看起来也挺平庸)。
考虑到上面几个因素,目前的诉求如下:
拓展性
最好使用现有的工具
最好能和大语言模型集成
在某种程度上能承担一下第二大脑的检索功能
通过上面的分析,目前尝试的解决方案是基于Obsidian(黑曜石)+RSS拓展+LLM拓展来实现
考虑到多端同步的问题,我这里直接订阅了黑曜石的会员,我之前也尝试过使用插件或者第三方的服务来实现黑曜石的同步,但是多多少少都会面临版本控制或者同步不及时的问题。(当然还因为之前其他的几个仓库都是用这个同步的,加一个这个也不会再花钱)
信息量几乎为零的教程
首先在新建了远程仓库之后,打开本地仓库,连接远程仓库。
然后在第三方拓展安装rss reader:
添加订阅源:
关于订阅源有非常多的渠道,这里使用rss hub进行演示:

随便选其中的某个来源:
在页面的右上方点击:
可得:
点开是这样:
效果还算优雅,但是目前我想要做的是更多就是引入大语言模型,帮助我从中查找相关的内容。
有两个目的,第1个是查找记的笔记,另外一个是查找我订阅源中的目标信息
使用的插件是:
your-papa/obsidian-Smart2Brain: An Obsidian plugin to interact with your privacy focused AI-Assistant making your second brain even smarter! (github.com)
这个插件目前还没有被收入官方的插件库当中,所以需要手动安装,手动安装可以查看网络上的教程,这里就不再赘述了
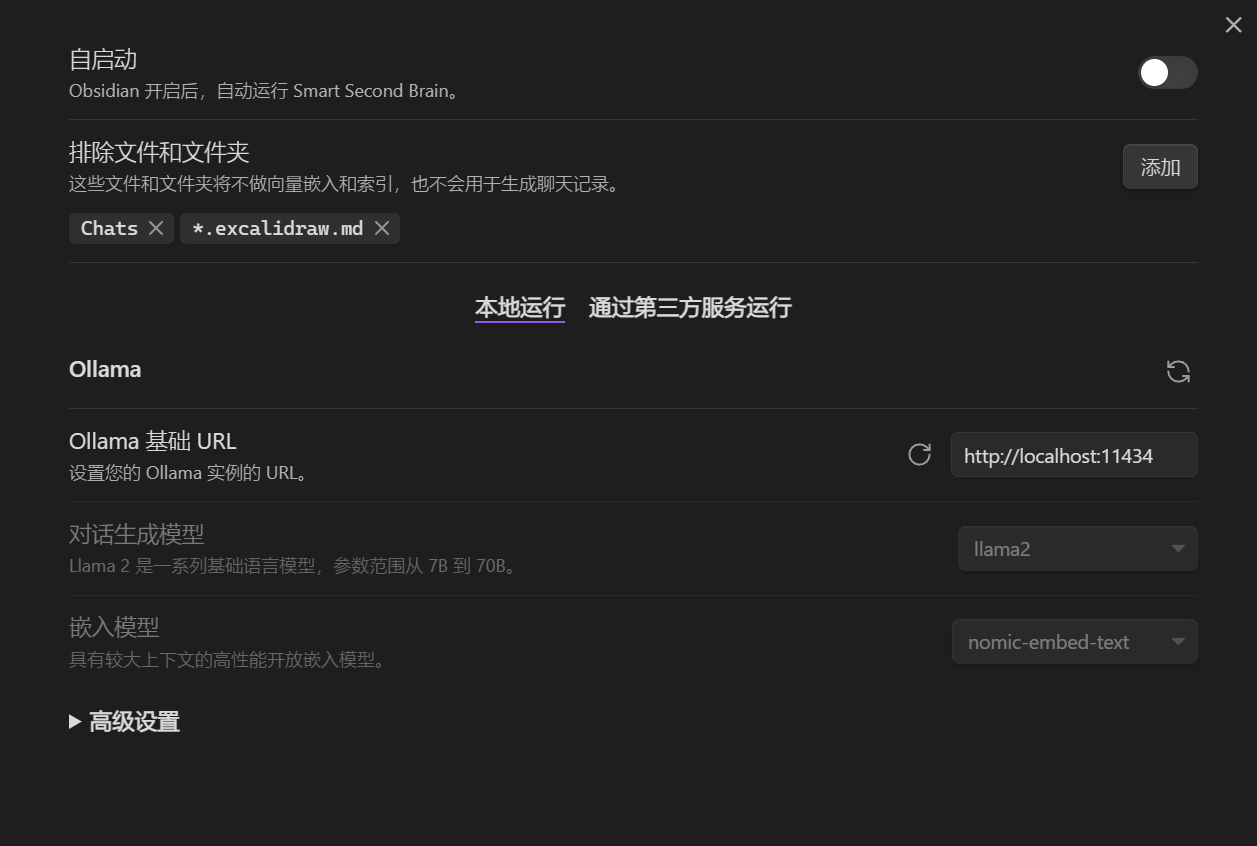
考虑到我绝大多数进行浏览和检索的过程都是在桌面完成的,因此这里使用本地的模型一方面是出于经济考虑,另一方面也是出于安全考虑。

Ollama相关的参考:
Ollama:本地大模型运行指南 - 知乎 (zhihu.com)
这里使用刚出的llama3的8b版本试试(作为参考,我使用4060):
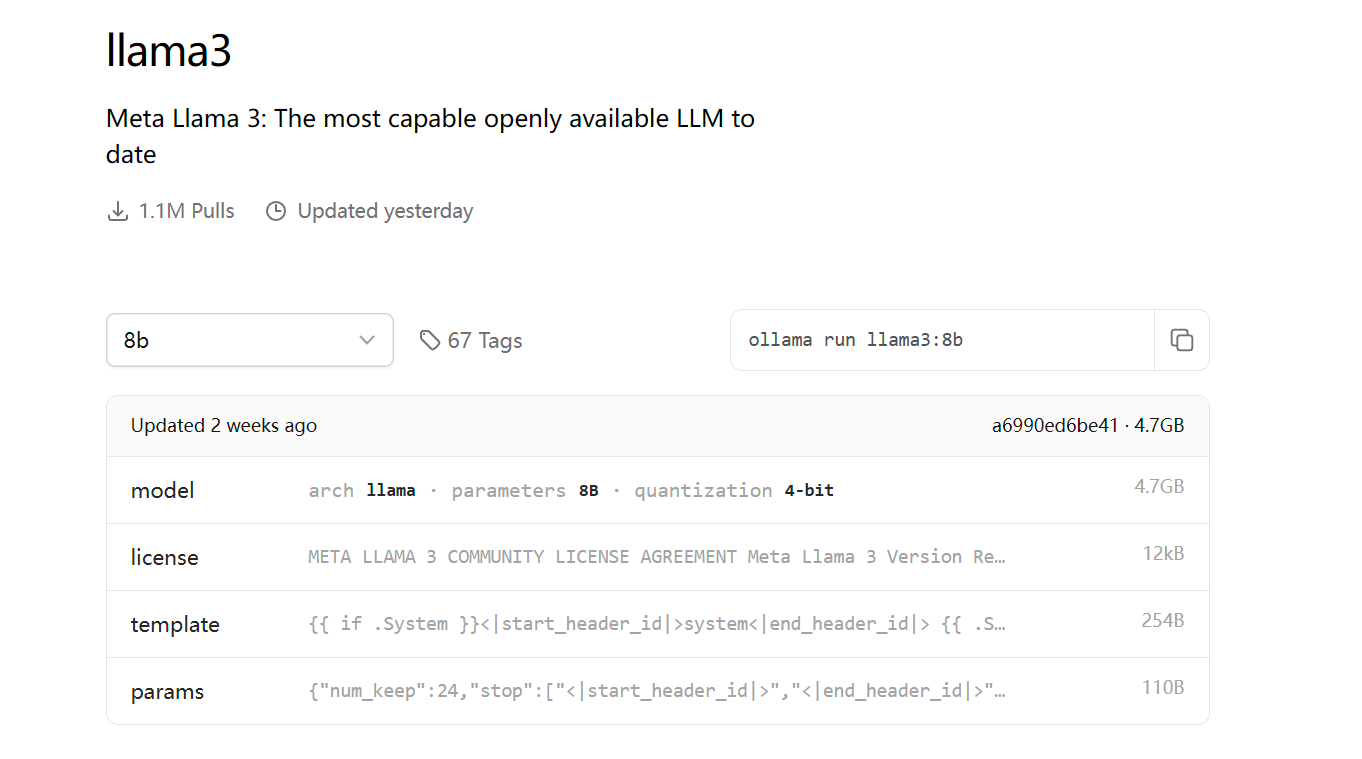
其实保险起见应该用千问的模型,毕竟对中文支持更好,但是这里出于尝鲜的考虑,试试这个吧
效果展示
我们先来试试,单纯的让他回答:
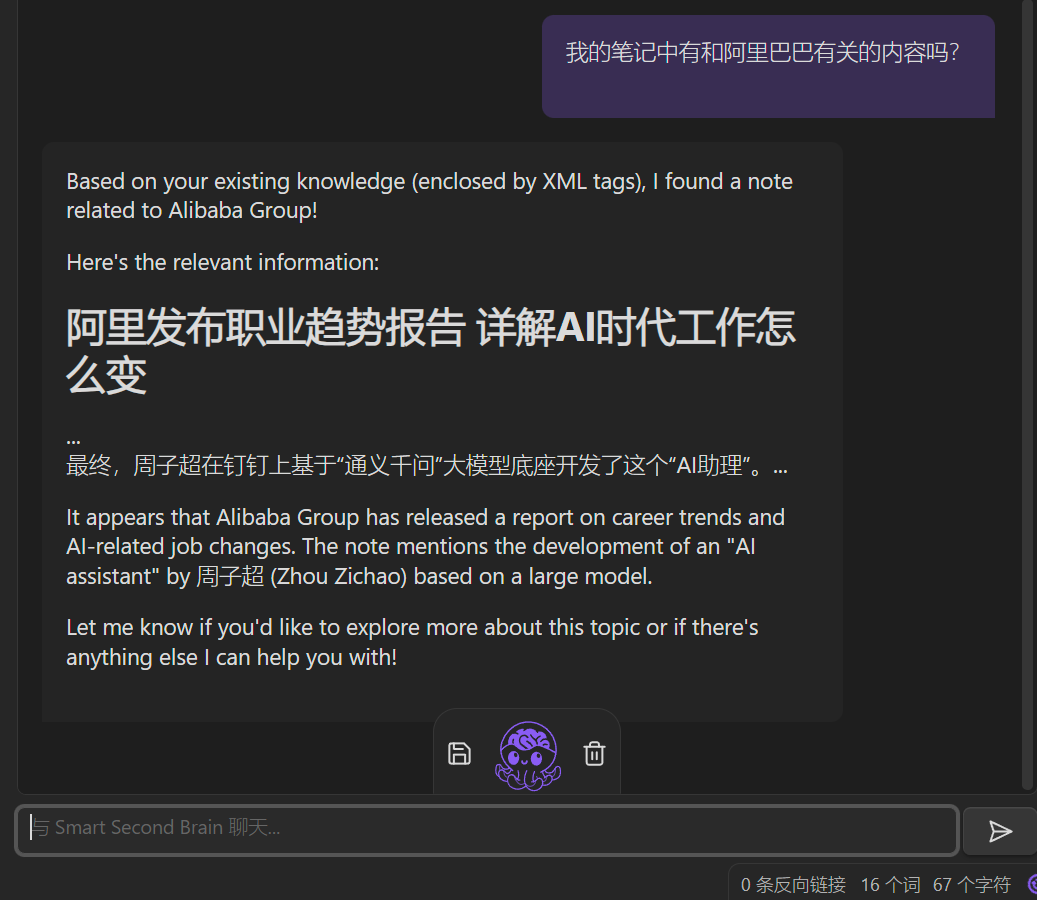
效果不错,就是目前插件还没有支持中文,这里需要提前让他用中文回答。
我们再来试试,让他来定位一下:
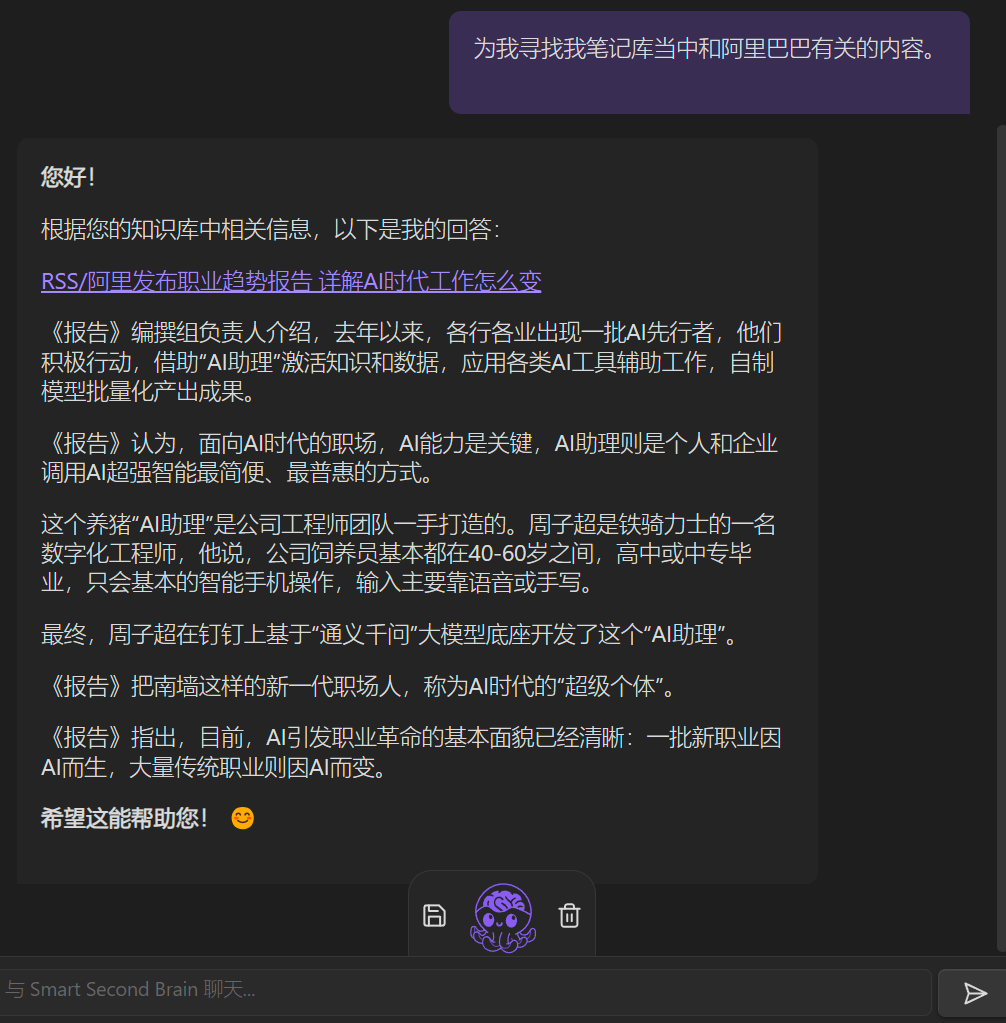
效果很棒,基本能满足我的需求了
对应的硬件压力:
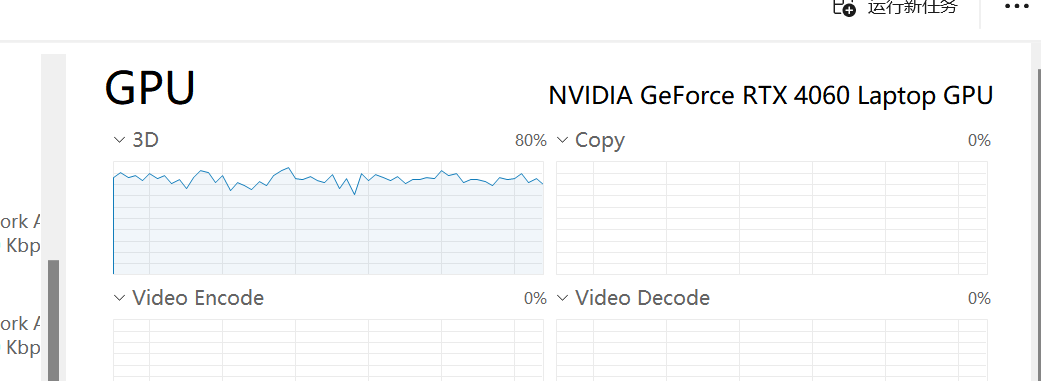
感觉还是可以接受的,毕竟不是长久挂载
后续:引入flomo
之前关注的一个插件项目最近更新了,可以将flomo和OB直接同步
Flomo可以被视作一个随身记录的软件,因为其双链特性和标签管理出众,其作者本身也是学习科学的研究者
项目链接:
jia6y/flomo-to-obsidian: Make Flomo Memos to Obsidian Notes (github.com)
然后flomo中的记录就可以做同步了
注:我在安装的时候遇到了Playwright的配置问题,安装了也不能使用,可以直接去把Playwright所在文件夹下的浏览器内核文件名称改成Playwright想要的,实测可以
然后需要去重新索引一下:
之后就可以进行
Ollama中遇到的坑:
无法运行、报错端口被占用等等:
首先管理员模式下运行:
ollama serve
然后执行:
$env:OLLAMA_ORIGINS="app://obsidian.md*"; ollama serve
基本上就没问题了